Sesión 3
Manejo y transformación de datos con dplyr y pipes
Universidad El Bosque
5 de junio de 2026
Agenda
- Datos sucios: el problema de partida
- Los verbos de dplyr:
select,rename,filter,mutate,summarise,group_by - El problema de combinar verbos sin pipe
- El pipe nativo
|>(y una nota sobre%>%) - Por qué Excel no es para datos de investigación
- Datos de psicología: limpieza y figuras
Parte 1
Datos sucios
La realidad de los datos
En investigación, los datos no llegan limpios. A menudo llegan así:
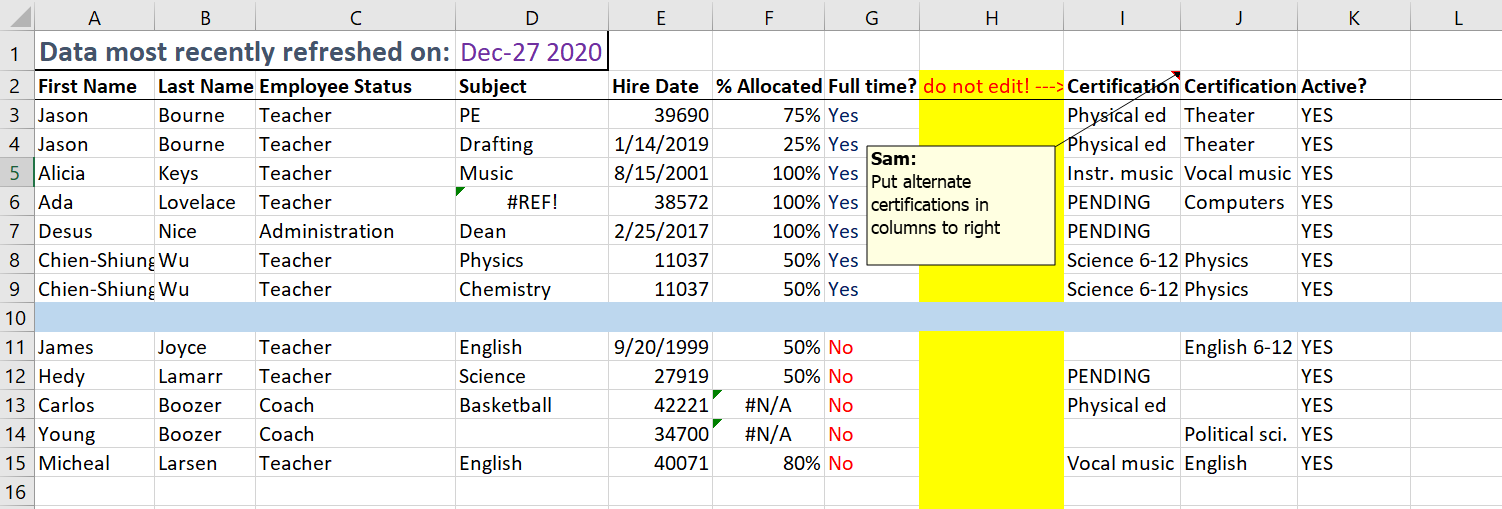
Esta es una hoja de Excel típica: filas de título, celdas combinadas, columnas con nombres que nadie va a querer escribir en código.
Descargar y cargar los datos
⬇ Descargar encuesta_bruta.xlsx
Guarda el archivo en tu computador (por ejemplo en el escritorio o en Documentos). Para cargarlo sin necesitar conocer rutas, usa el menú de RStudio:
Environment → Import Dataset → From Excel…
- Navega hasta el archivo y selecciónalo
- En la vista previa verás que la primera fila es el título del estudio: ajusta Skip a
2 - Verifica que la vista previa ya muestre las columnas correctas
- Copia el código del recuadro Code Preview antes de hacer clic en Import
- Pégalo en tu script y ejecútalo desde ahí
El paso más importante es copiar el código. Sin eso, la próxima vez que abras RStudio tendrás que repetir todo el proceso. Con el código en el script, basta con ejecutarlo una vez.
El código que genera RStudio
El código que aparece en Code Preview se verá así (con la ruta a tu archivo):
Pégalo en tu script. La ruta será absoluta (depende de tu computador), lo cual está bien por ahora. En la Sesión 4 crearás un proyecto organizado y moverás este archivo a una carpeta datos/, donde podrás cargarlo con read_excel("datos/encuesta_bruta.xlsx", skip = 2).
Rows: 180
Columns: 17
$ id <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 1…
$ nombre <chr> "P001", "P002", "P003", "P004", "P005", "P006", "P007", …
$ edad <dbl> 30, 26, 18, 23, 30, 28, 29, 21, 22, 29, 27, 19, 25, 20, …
$ Género <chr> "Hombre", "mujer", "Mujer", "Mujer", "Mujer", "M", "Homb…
$ carrera <chr> "psicología", "Medicina", "Medicina", "Psicología", "Enf…
$ semestre <dbl> 8, 9, 1, 10, 7, 2, 4, 3, 3, 8, 10, 8, 4, 3, 2, 7, 1, 2, …
$ `GAD 1` <dbl> 1, 2, 1, 3, 1, 3, 1, 2, 0, 3, 2, 3, 1, 1, 2, 1, 1, 3, 0,…
$ `GAD 2` <dbl> 2, 1, 2, 3, 0, 0, 2, 3, 3, 1, 0, 3, 2, 1, 1, 1, 2, 2, 3,…
$ `GAD 3` <dbl> 3, 2, 1, 0, 1, 2, 0, 3, 2, 2, 3, 3, 1, 1, 0, 2, 0, 0, 2,…
$ `GAD 4` <dbl> 1, 0, 3, 0, 1, 0, 3, 1, 2, 0, 1, 1, 2, 2, 3, 1, 3, 3, 2,…
$ `GAD 5` <dbl> 0, 2, 1, 1, 0, 0, 3, 3, 2, 1, 0, 1, 2, 1, 2, 3, 2, 2, 1,…
$ `GAD 6` <dbl> 2, 3, 3, 3, 3, 0, 0, 1, 3, 0, 1, 1, 3, 1, 3, 3, 1, 0, 0,…
$ `GAD 7` <dbl> 2, 2, 1, 2, 1, 2, 0, 0, 0, 3, 0, 0, 2, 1, 3, 0, 3, 2, 3,…
$ observaciones <chr> "revisar", NA, NA, NA, "revisar", "revisar", NA, NA, NA,…
$ ...15 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ ...16 <chr> NA, NA, "Nata, mira esto", "Edad mediana", NA, NA, NA, N…
$ ...17 <dbl> NA, NA, NA, 23, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …180 filas, columnas con nombre. Pero quedan columnas extra al final (...15, ...16, ...17) por el texto y el cálculo que alguien dejó fuera de la tabla.
¿Qué necesitamos?
Para dejar encuesta_bruta lista para analizar, necesitamos:
- Eliminar las columnas fantasma (
...15,...16,...17) y las innecesarias (nombre,observaciones) - Renombrar columnas con espacios o tildes (
Género→genero,GAD 1→gad_1…) - Transformar columnas: estandarizar categorías inconsistentes (“Mujer” / “mujer” / “M”)
- Crear columnas nuevas: puntaje total, nivel de ansiedad
- Resumir por grupos
Todas esas operaciones las resuelve dplyr. Pero primero aprendemos las herramientas.
Parte 2
Los verbos de dplyr

dplyr en el ecosistema tidyverse
dplyr es parte de tidyverse y trabaja en perfecta sintonía con ggplot2: ambos esperan datos en formato tabular (filas = observaciones, columnas = variables).
Sus funciones principales se llaman verbos:
| Verbo | Qué hace |
|---|---|
select() |
Selecciona columnas |
rename() |
Renombra columnas |
filter() |
Filtra filas según una condición |
mutate() |
Crea o sobreescribe columnas |
summarise() |
Resume datos en una o pocas filas |
group_by() |
Agrupa filas para operar por grupo |
Nuestros datos de práctica
Usaremos pinguinos (los pingüinos de Palmer, ya conocidos de la sesión anterior):
Rows: 333
Columns: 8
$ species <fct> Adelie, Adelie, Adelie, Adelie, Adelie, Adelie, Adel…
$ island <fct> Torgersen, Torgersen, Torgersen, Torgersen, Torgerse…
$ bill_length_mm <dbl> 39.1, 39.5, 40.3, 36.7, 39.3, 38.9, 39.2, 41.1, 38.6…
$ bill_depth_mm <dbl> 18.7, 17.4, 18.0, 19.3, 20.6, 17.8, 19.6, 17.6, 21.2…
$ flipper_length_mm <int> 181, 186, 195, 193, 190, 181, 195, 182, 191, 198, 18…
$ body_mass_g <int> 3750, 3800, 3250, 3450, 3650, 3625, 4675, 3200, 3800…
$ sex <fct> male, female, female, female, male, female, male, fe…
$ year <int> 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007…Verbo 1
select() · elegir columnas
select(): elegir columnas por nombre
# A tibble: 333 × 3
species body_mass_g sex
<fct> <int> <fct>
1 Adelie 3750 male
2 Adelie 3800 female
3 Adelie 3250 female
4 Adelie 3450 female
5 Adelie 3650 male
6 Adelie 3625 female
7 Adelie 4675 male
8 Adelie 3200 female
9 Adelie 3800 male
10 Adelie 4400 male
# ℹ 323 more rowsselect(): excluir con -
# A tibble: 333 × 6
species bill_length_mm bill_depth_mm flipper_length_mm body_mass_g sex
<fct> <dbl> <dbl> <int> <int> <fct>
1 Adelie 39.1 18.7 181 3750 male
2 Adelie 39.5 17.4 186 3800 female
3 Adelie 40.3 18 195 3250 female
4 Adelie 36.7 19.3 193 3450 female
5 Adelie 39.3 20.6 190 3650 male
6 Adelie 38.9 17.8 181 3625 female
7 Adelie 39.2 19.6 195 4675 male
8 Adelie 41.1 17.6 182 3200 female
9 Adelie 38.6 21.2 191 3800 male
10 Adelie 34.6 21.1 198 4400 male
# ℹ 323 more rowsselect(): patrones de nombre
starts_with(), ends_with() y contains() seleccionan columnas según su nombre:
# A tibble: 333 × 3
species bill_length_mm bill_depth_mm
<fct> <dbl> <dbl>
1 Adelie 39.1 18.7
2 Adelie 39.5 17.4
3 Adelie 40.3 18
4 Adelie 36.7 19.3
5 Adelie 39.3 20.6
6 Adelie 38.9 17.8
7 Adelie 39.2 19.6
8 Adelie 41.1 17.6
9 Adelie 38.6 21.2
10 Adelie 34.6 21.1
# ℹ 323 more rows# A tibble: 333 × 4
species bill_length_mm bill_depth_mm flipper_length_mm
<fct> <dbl> <dbl> <int>
1 Adelie 39.1 18.7 181
2 Adelie 39.5 17.4 186
3 Adelie 40.3 18 195
4 Adelie 36.7 19.3 193
5 Adelie 39.3 20.6 190
6 Adelie 38.9 17.8 181
7 Adelie 39.2 19.6 195
8 Adelie 41.1 17.6 182
9 Adelie 38.6 21.2 191
10 Adelie 34.6 21.1 198
# ℹ 323 more rowsVerbo 2
rename(): renombrar columnas
rename(): renombrar columnas
# A tibble: 333 × 8
especie island bill_length_mm bill_depth_mm flipper_length_mm masa_g sex
<fct> <fct> <dbl> <dbl> <int> <int> <fct>
1 Adelie Torgersen 39.1 18.7 181 3750 male
2 Adelie Torgersen 39.5 17.4 186 3800 fema…
3 Adelie Torgersen 40.3 18 195 3250 fema…
4 Adelie Torgersen 36.7 19.3 193 3450 fema…
5 Adelie Torgersen 39.3 20.6 190 3650 male
6 Adelie Torgersen 38.9 17.8 181 3625 fema…
7 Adelie Torgersen 39.2 19.6 195 4675 male
8 Adelie Torgersen 41.1 17.6 182 3200 fema…
9 Adelie Torgersen 38.6 21.2 191 3800 male
10 Adelie Torgersen 34.6 21.1 198 4400 male
# ℹ 323 more rows
# ℹ 1 more variable: year <int>La sintaxis es siempre nuevo_nombre = nombre_actual.
Verbo 3
filter() · elegir filas
filter(): filas que cumplen una condición
# A tibble: 146 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen 36.7 19.3 193 3450
5 Adelie Torgersen 39.3 20.6 190 3650
6 Adelie Torgersen 38.9 17.8 181 3625
7 Adelie Torgersen 39.2 19.6 195 4675
8 Adelie Torgersen 41.1 17.6 182 3200
9 Adelie Torgersen 38.6 21.2 191 3800
10 Adelie Torgersen 34.6 21.1 198 4400
# ℹ 136 more rows
# ℹ 2 more variables: sex <fct>, year <int>Usa == para comparar igualdad (no =). Los operadores habituales: == igual, != distinto, >, <, >=, <=.
filter(): varias condiciones con AND
Separar condiciones con , o con & equivalen a AND (se deben cumplir todas):
# A tibble: 34 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.2 19.6 195 4675
2 Adelie Torgersen 34.6 21.1 198 4400
3 Adelie Torgersen 42.5 20.7 197 4500
4 Adelie Torgersen 46 21.5 194 4200
5 Adelie Dream 39.2 21.1 196 4150
6 Adelie Dream 39.8 19.1 184 4650
7 Adelie Dream 44.1 19.7 196 4400
8 Adelie Dream 39.6 18.8 190 4600
9 Adelie Dream 42.3 21.2 191 4150
10 Adelie Biscoe 40.1 18.9 188 4300
# ℹ 24 more rows
# ℹ 2 more variables: sex <fct>, year <int>filter(): condiciones con OR
El operador | significa OR (basta con que se cumpla al menos una):
# A tibble: 96 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Gentoo Biscoe 50 16.3 230 5700
2 Gentoo Biscoe 50 15.2 218 5700
3 Gentoo Biscoe 49 16.1 216 5550
4 Gentoo Biscoe 48.4 14.6 213 5850
5 Gentoo Biscoe 49.3 15.7 217 5850
6 Gentoo Biscoe 49.2 15.2 221 6300
7 Gentoo Biscoe 50.2 14.3 218 5700
8 Gentoo Biscoe 47.8 15 215 5650
9 Gentoo Biscoe 50 15.3 220 5550
10 Gentoo Biscoe 59.6 17 230 6050
# ℹ 86 more rows
# ℹ 2 more variables: sex <fct>, year <int>filter(): el operador %in%
%in% comprueba si un valor pertenece a un conjunto. Es más limpio que escribir varios OR:
Es equivalente a:
# A tibble: 214 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen 36.7 19.3 193 3450
5 Adelie Torgersen 39.3 20.6 190 3650
6 Adelie Torgersen 38.9 17.8 181 3625
7 Adelie Torgersen 39.2 19.6 195 4675
8 Adelie Torgersen 41.1 17.6 182 3200
9 Adelie Torgersen 38.6 21.2 191 3800
10 Adelie Torgersen 34.6 21.1 198 4400
# ℹ 204 more rows
# ℹ 2 more variables: sex <fct>, year <int>%in% devuelve TRUE si el valor de la izquierda aparece en algún lugar del vector de la derecha. ! invierte: !species %in% c("Adelie", "Chinstrap") excluye esas dos especies.
Actividad · 2 min
AND vs. OR: ¿quién se incluye?
Verbo 4
mutate() · crear y transformar columnas
mutate(): crear una columna nueva
# A tibble: 333 × 9
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen 36.7 19.3 193 3450
5 Adelie Torgersen 39.3 20.6 190 3650
6 Adelie Torgersen 38.9 17.8 181 3625
7 Adelie Torgersen 39.2 19.6 195 4675
8 Adelie Torgersen 41.1 17.6 182 3200
9 Adelie Torgersen 38.6 21.2 191 3800
10 Adelie Torgersen 34.6 21.1 198 4400
# ℹ 323 more rows
# ℹ 3 more variables: sex <fct>, year <int>, body_mass_kg <dbl>La nueva columna se añade al final. El data frame original no cambia.
mutate(): sobreescribir una columna existente
Si usas el nombre de una columna que ya existe, la sobreescribe:
# A tibble: 333 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <dbl>
1 Adelie Torgersen 39.1 18.7 181 3.75
2 Adelie Torgersen 39.5 17.4 186 3.8
3 Adelie Torgersen 40.3 18 195 3.25
4 Adelie Torgersen 36.7 19.3 193 3.45
5 Adelie Torgersen 39.3 20.6 190 3.65
6 Adelie Torgersen 38.9 17.8 181 3.62
7 Adelie Torgersen 39.2 19.6 195 4.68
8 Adelie Torgersen 41.1 17.6 182 3.2
9 Adelie Torgersen 38.6 21.2 191 3.8
10 Adelie Torgersen 34.6 21.1 198 4.4
# ℹ 323 more rows
# ℹ 2 more variables: sex <fct>, year <int>Las columnas body_mass_g y body_mass_kg harían lo mismo aquí. La diferencia es si quieres conservar el valor original con otro nombre o simplemente transformar la columna en su lugar. En el análisis de datos, sobreescribir es útil para estandarizar unidades, convertir tipos o corregir errores de codificación.
mutate() + case_when(): recodificar
case_when() evalúa condiciones de arriba a abajo y asigna el valor de la primera que se cumpla:
mutate(
pinguinos,
tamano = case_when(
body_mass_g >= 5000 ~ "Grande",
body_mass_g >= 3500 ~ "Mediano",
.default = "Pequeño"
)
)# A tibble: 333 × 9
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen 36.7 19.3 193 3450
5 Adelie Torgersen 39.3 20.6 190 3650
6 Adelie Torgersen 38.9 17.8 181 3625
7 Adelie Torgersen 39.2 19.6 195 4675
8 Adelie Torgersen 41.1 17.6 182 3200
9 Adelie Torgersen 38.6 21.2 191 3800
10 Adelie Torgersen 34.6 21.1 198 4400
# ℹ 323 more rows
# ℹ 3 more variables: sex <fct>, year <int>, tamano <chr>Verbos 5 y 6
summarise() y group_by()
summarise(): colapsar en un resumen
# A tibble: 1 × 3
masa_media masa_sd n
<dbl> <dbl> <int>
1 4207. 805. 333n() cuenta el número de filas. Las demás son funciones estadísticas normales.
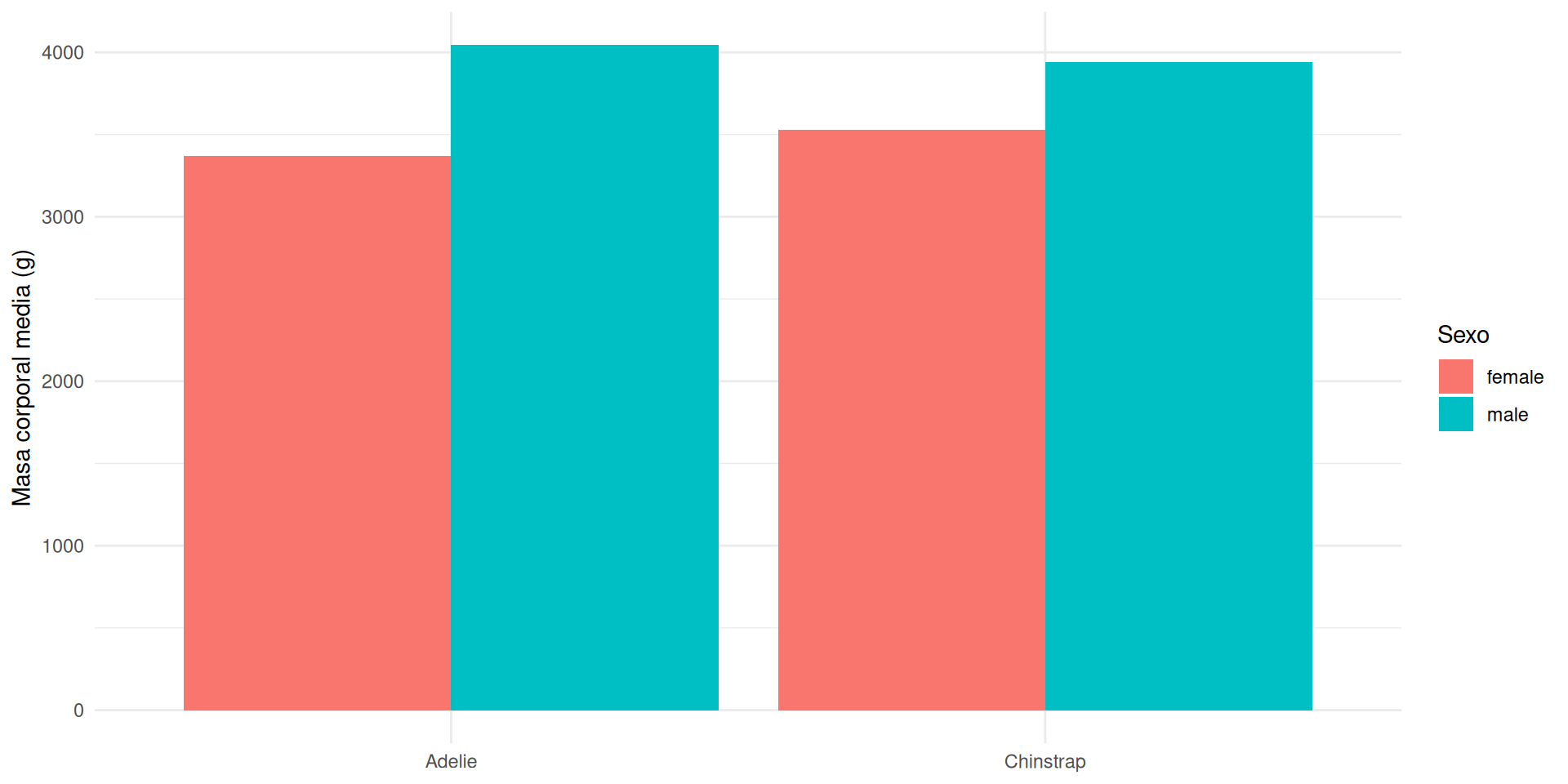
group_by() + summarise(): resumen por grupos
group_by() divide el data frame en grupos; summarise() opera dentro de cada uno. Podemos agrupar por una o más variables:
por_esp_sexo <- group_by(pinguinos, species, sex)
summarise(por_esp_sexo,
masa_media = mean(body_mass_g),
n = n()
)# A tibble: 6 × 4
# Groups: species [3]
species sex masa_media n
<fct> <fct> <dbl> <int>
1 Adelie female 3369. 73
2 Adelie male 4043. 73
3 Chinstrap female 3527. 34
4 Chinstrap male 3939. 34
5 Gentoo female 4680. 58
6 Gentoo male 5485. 61group_by() + mutate(): calcular dentro de grupos
A diferencia de summarise(), mutate() devuelve una fila por observación original:
por_especie <- group_by(pinguinos, species)
mutate(por_especie, masa_vs_especie = body_mass_g - mean(body_mass_g))# A tibble: 333 × 9
# Groups: species [3]
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen 36.7 19.3 193 3450
5 Adelie Torgersen 39.3 20.6 190 3650
6 Adelie Torgersen 38.9 17.8 181 3625
7 Adelie Torgersen 39.2 19.6 195 4675
8 Adelie Torgersen 41.1 17.6 182 3200
9 Adelie Torgersen 38.6 21.2 191 3800
10 Adelie Torgersen 34.6 21.1 198 4400
# ℹ 323 more rows
# ℹ 3 more variables: sex <fct>, year <int>, masa_vs_especie <dbl>Actividad · 8 min
Encadenar verbos
Con pinguinos, aplica los verbos que conoces y:
- Filtra solo las observaciones de la isla Dream
- Añade una columna
masa_kg(masa en kilogramos) - Selecciona solo
species,sex,flipper_length_mmymasa_kg
¿Qué dificultad aparece al hacerlo en pasos separados?
Parte 3
El problema de combinar verbos
Varios pasos, varios objetos
Cuando necesitas aplicar varios verbos, sin pipe tienes que guardar cada paso:
paso1 <- select(pinguinos, species, sex, body_mass_g)
paso2 <- filter(paso1, sex == "female")
paso3 <- mutate(paso2, body_mass_kg = body_mass_g / 1000)
paso4 <- group_by(paso3, species)
paso5 <- summarise(paso4, masa_media_kg = mean(body_mass_kg))
paso5# A tibble: 3 × 2
species masa_media_kg
<fct> <dbl>
1 Adelie 3.37
2 Chinstrap 3.53
3 Gentoo 4.68El entorno se llena de paso1… paso5. ¿Cuál es el definitivo?
O todo anidado (leer de adentro hacia afuera)
summarise(
group_by(
mutate(
filter(
select(pinguinos, species, sex, body_mass_g),
sex == "female"
),
body_mass_kg = body_mass_g / 1000
),
species
),
masa_media_kg = mean(body_mass_kg)
)# A tibble: 3 × 2
species masa_media_kg
<fct> <dbl>
1 Adelie 3.37
2 Chinstrap 3.53
3 Gentoo 4.68El orden de ejecución va de adentro hacia afuera, pero el orden de lectura va de arriba hacia abajo. Una sola coma en el lugar equivocado rompe todo.
Parte 4
El pipe |>
La solución: el pipe nativo |>
El pipe toma el resultado de la izquierda y lo pasa como primer argumento de la función de la derecha:
Con pipe, el código se lee de arriba a abajo, como una secuencia de pasos.
El mismo ejemplo, con pipe
pinguinos |>
select(species, sex, body_mass_g) |>
filter(sex == "female") |>
mutate(body_mass_kg = body_mass_g / 1000) |>
group_by(species) |>
summarise(masa_media_kg = mean(body_mass_kg))# A tibble: 3 × 2
species masa_media_kg
<fct> <dbl>
1 Adelie 3.37
2 Chinstrap 3.53
3 Gentoo 4.68Un solo resultado sin objetos intermedios. Se lee como una receta.
Atajo de teclado
En RStudio, el pipe se inserta con:
Windows / Linux: Ctrl + Shift + M

Mac: Cmd + Shift + M

Verifica que el atajo esté configurado para |> y no para %>%. Ve a Tools > Global Options > Code > Editing y marca “Use native pipe operator |>”.
El pipe de magrittr: %>%
Antes de que R 4.1 (2021) introdujera |>, el pipe más usado venía del paquete magrittr (parte de tidyverse).
Si ves %>% en tutoriales, libros o código de otras personas, hace lo mismo que |> en la gran mayoría de los casos.
Hoy se recomienda |> por ser nativo (no requiere paquetes adicionales). %>% tiene algunas funciones avanzadas para casos muy específicos, pero para el trabajo cotidiano son equivalentes.
Pipe + ggplot2: el pipeline completo
Los datos pasan directamente de dplyr a ggplot2 sin crear objetos intermedios:
Parte 5
Por qué Excel no es para datos de investigación
Excel no es machine-readable
Un archivo machine-readable (legible por máquina) tiene un formato que un programa puede interpretar directamente, fila por fila, sin que haya ninguna ambigüedad.
Excel no lo garantiza porque:
- Permite mezclar datos, cálculos, gráficos, notas y texto decorativo en la misma hoja
- Una celda puede contener algo como “3,5 kg de masa corporal (valor estimado)”
- Las celdas combinadas y las filas de títulos extra dañan cualquier estructura tabular
- El formato
.xlsxalmacena colores, fuentes y bordes junto a los datos, haciéndolo pesado y dependiente de un programa propietario
Un CSV o un data frame en R son machine-readable: cada columna tiene un tipo fijo y cada fila es una observación.
Más problemas de Excel
Reproducibilidad
- Cuando calculas algo en Excel, queda el resultado pero no el proceso
- Cualquier edición a los datos originales es permanente e invisible
- Dos personas haciendo “lo mismo” en Excel pueden obtener resultados distintos
Escala
- Serios problemas con tablas muy grandes (más de unos cientos de miles de filas)
- Un archivo con muchas fórmulas se vuelve lento e inestable
Formato propietario
- Depende de Microsoft para abrirlo correctamente
- Distintas versiones de Excel abren el mismo archivo de forma diferente
- En la próxima sesión veremos formatos abiertos como CSV, que evitan este problema
Tipos de datos
- Excel adivina el tipo de cada celda, y a veces se equivoca de forma silenciosa
El enemigo silencioso: Excel modifica datos

El enemigo silencioso: Excel modifica datos
Excel convierte datos automáticamente, con consecuencias que a veces son difíciles de detectar.
Casos documentados:
- El gen
SEPT2(Septin-2) se convierte en “Sep-2” (fecha: septiembre 2) DEC1se convierte en “1-Dic”- IDs numéricos largos como
123456789012se redondean en silencio - Fechas en formato
DD/MM/AAAAse invierten al copiar entre sistemas con regiones distintas
Los datos parecen correctos: por eso estos errores se publican.
Un estudio encontró que el 30% de los artículos de genómica publicados en revistas científicas tenían errores en nombres de genes causados por Excel.
Ziemann et al. (2016). Genome Biology.
El principio de reproducibilidad
La diferencia entre R y Excel es metodológica:
Con Excel
Los datos originales se editan directamente. No queda registro de qué cambió, cuándo ni por qué. El proceso no se puede auditar ni replicar.
Con R
El archivo de datos no se toca. El script documenta cada transformación. Cualquier persona (incluyendo a ti en seis meses) puede ejecutar el script y obtener exactamente el mismo resultado.
Regla: los datos originales no se tocan. El script es el registro permanente de todo lo que hiciste con ellos.
Cómo diseñar bien una base de datos
Muchos problemas de limpieza se evitan desde el diseño de la encuesta.
Errores comunes
- Preguntas abiertas donde una escala es suficiente (si quieres medir estrés, usa 1-5, no texto libre)
- Categorías escritas de formas distintas: “Mujer”, “mujer”, “MUJER”, “M”
- Dos variables en una celda: “Psicología, 3er semestre”
- Combinar datos, cálculos y notas en la misma hoja
Buenas prácticas
- Una variable por columna, una observación por fila
- Nombres de columna sin espacios ni acentos (
snake_case; por ejemplonivel_ansiedad) - Categorías fijas con listas desplegables (Google Forms, KoboToolbox)
- Código de participante, no nombre (para anonimizar desde el inicio)
- Un archivo por fuente de datos
Parte 6
Aplicación: datos de psicología
El GAD-7
El GAD-7 (Generalized Anxiety Disorder 7-item scale) es un cuestionario de 7 ítems, cada uno puntuado de 0 a 3. La suma da un puntaje de 0 a 21.
| Puntaje | Nivel |
|---|---|
| 0–4 | Mínima |
| 5–9 | Leve |
| 10–14 | Moderada |
| 15–21 | Severa |
Nuestra base de datos simulada tiene respuestas de 180 estudiantes universitarios con variables demográficas. Viene con los problemas típicos que ya vimos.
Los datos en bruto
Rows: 180
Columns: 17
$ id <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 1…
$ nombre <chr> "P001", "P002", "P003", "P004", "P005", "P006", "P007", …
$ edad <dbl> 30, 26, 18, 23, 30, 28, 29, 21, 22, 29, 27, 19, 25, 20, …
$ Género <chr> "Hombre", "mujer", "Mujer", "Mujer", "Mujer", "M", "Homb…
$ carrera <chr> "psicología", "Medicina", "Medicina", "Psicología", "Enf…
$ semestre <dbl> 8, 9, 1, 10, 7, 2, 4, 3, 3, 8, 10, 8, 4, 3, 2, 7, 1, 2, …
$ `GAD 1` <dbl> 1, 2, 1, 3, 1, 3, 1, 2, 0, 3, 2, 3, 1, 1, 2, 1, 1, 3, 0,…
$ `GAD 2` <dbl> 2, 1, 2, 3, 0, 0, 2, 3, 3, 1, 0, 3, 2, 1, 1, 1, 2, 2, 3,…
$ `GAD 3` <dbl> 3, 2, 1, 0, 1, 2, 0, 3, 2, 2, 3, 3, 1, 1, 0, 2, 0, 0, 2,…
$ `GAD 4` <dbl> 1, 0, 3, 0, 1, 0, 3, 1, 2, 0, 1, 1, 2, 2, 3, 1, 3, 3, 2,…
$ `GAD 5` <dbl> 0, 2, 1, 1, 0, 0, 3, 3, 2, 1, 0, 1, 2, 1, 2, 3, 2, 2, 1,…
$ `GAD 6` <dbl> 2, 3, 3, 3, 3, 0, 0, 1, 3, 0, 1, 1, 3, 1, 3, 3, 1, 0, 0,…
$ `GAD 7` <dbl> 2, 2, 1, 2, 1, 2, 0, 0, 0, 3, 0, 0, 2, 1, 3, 0, 3, 2, 3,…
$ observaciones <chr> "revisar", NA, NA, NA, "revisar", "revisar", NA, NA, NA,…
$ ...15 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ ...16 <chr> NA, NA, "Nata, mira esto", "Edad mediana", NA, NA, NA, N…
$ ...17 <dbl> NA, NA, NA, 23, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …Paso 1: explorar las columnas problemáticas
Antes de transformar, revisamos qué valores hay:
# A tibble: 7 × 2
Género n
<chr> <int>
1 Mujer 55
2 Hombre 44
3 mujer 34
4 hombre 19
5 H 12
6 M 10
7 No binario 6Paso 2: quitar columnas y estandarizar nombres
encuesta <- encuesta_bruta |>
select(-nombre, -observaciones, -starts_with("...")) |>
rename(genero = `Género`) |>
rename_with(~ tolower(gsub(" ", "_", .)), starts_with("GAD"))
glimpse(encuesta)Rows: 180
Columns: 12
$ id <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18…
$ edad <dbl> 30, 26, 18, 23, 30, 28, 29, 21, 22, 29, 27, 19, 25, 20, 30, 1…
$ genero <chr> "Hombre", "mujer", "Mujer", "Mujer", "Mujer", "M", "Hombre", …
$ carrera <chr> "psicología", "Medicina", "Medicina", "Psicología", "Enfermer…
$ semestre <dbl> 8, 9, 1, 10, 7, 2, 4, 3, 3, 8, 10, 8, 4, 3, 2, 7, 1, 2, 1, 1,…
$ gad_1 <dbl> 1, 2, 1, 3, 1, 3, 1, 2, 0, 3, 2, 3, 1, 1, 2, 1, 1, 3, 0, 2, 3…
$ gad_2 <dbl> 2, 1, 2, 3, 0, 0, 2, 3, 3, 1, 0, 3, 2, 1, 1, 1, 2, 2, 3, 1, 3…
$ gad_3 <dbl> 3, 2, 1, 0, 1, 2, 0, 3, 2, 2, 3, 3, 1, 1, 0, 2, 0, 0, 2, 0, 0…
$ gad_4 <dbl> 1, 0, 3, 0, 1, 0, 3, 1, 2, 0, 1, 1, 2, 2, 3, 1, 3, 3, 2, 1, 3…
$ gad_5 <dbl> 0, 2, 1, 1, 0, 0, 3, 3, 2, 1, 0, 1, 2, 1, 2, 3, 2, 2, 1, 1, 0…
$ gad_6 <dbl> 2, 3, 3, 3, 3, 0, 0, 1, 3, 0, 1, 1, 3, 1, 3, 3, 1, 0, 0, 0, 0…
$ gad_7 <dbl> 2, 2, 1, 2, 1, 2, 0, 0, 0, 3, 0, 0, 2, 1, 3, 0, 3, 2, 3, 2, 1…select(-starts_with("...")) elimina las columnas fantasma generadas por las anotaciones fuera de la tabla. rename_with() convierte "GAD 1" en "gad_1", y así con todos.
Paso 3: estandarizar categorías y calcular puntaje
encuesta <- encuesta |>
mutate(
genero = case_when(
genero %in% c("Mujer", "mujer", "M") ~ "Mujer",
genero %in% c("Hombre", "hombre", "H") ~ "Hombre",
.default = genero
),
carrera = case_when(
tolower(carrera) %in% c("psicología", "psicologia") ~ "Psicología",
tolower(carrera) == "medicina" ~ "Medicina",
tolower(carrera) %in% c("enfermería", "enfermeria") ~ "Enfermería",
.default = carrera
),
ansiedad_total = gad_1 + gad_2 + gad_3 + gad_4 + gad_5 + gad_6 + gad_7,
nivel_ansiedad = case_when(
ansiedad_total <= 4 ~ "Mínima",
ansiedad_total <= 9 ~ "Leve",
ansiedad_total <= 14 ~ "Moderada",
ansiedad_total >= 15 ~ "Severa"
),
nivel_ansiedad = factor(nivel_ansiedad,
levels = c("Mínima", "Leve", "Moderada", "Severa")
)
)Paso 4: verificar el resultado
Hacer esto manualmente en Excel puede funcionar para conjuntos pequeños, pero resulta inviable con bases muy grandes y es propenso a errores. Aquí, como no modificamos los datos originales, podemos rehacer el código y volver a ejecutar para obtener un resultado limpio.
Un script bien escrito reduce significativamente los errores humanos y hace el análisis reproducible y transparente
Resumen por grupo
ungroup(): liberar el agrupamiento
group_by() deja el data frame agrupado hasta que se use ungroup() explícitamente. Sin él, operaciones posteriores (incluyendo figuras) pueden comportarse de forma inesperada.
Figura 1: distribución del puntaje GAD-7
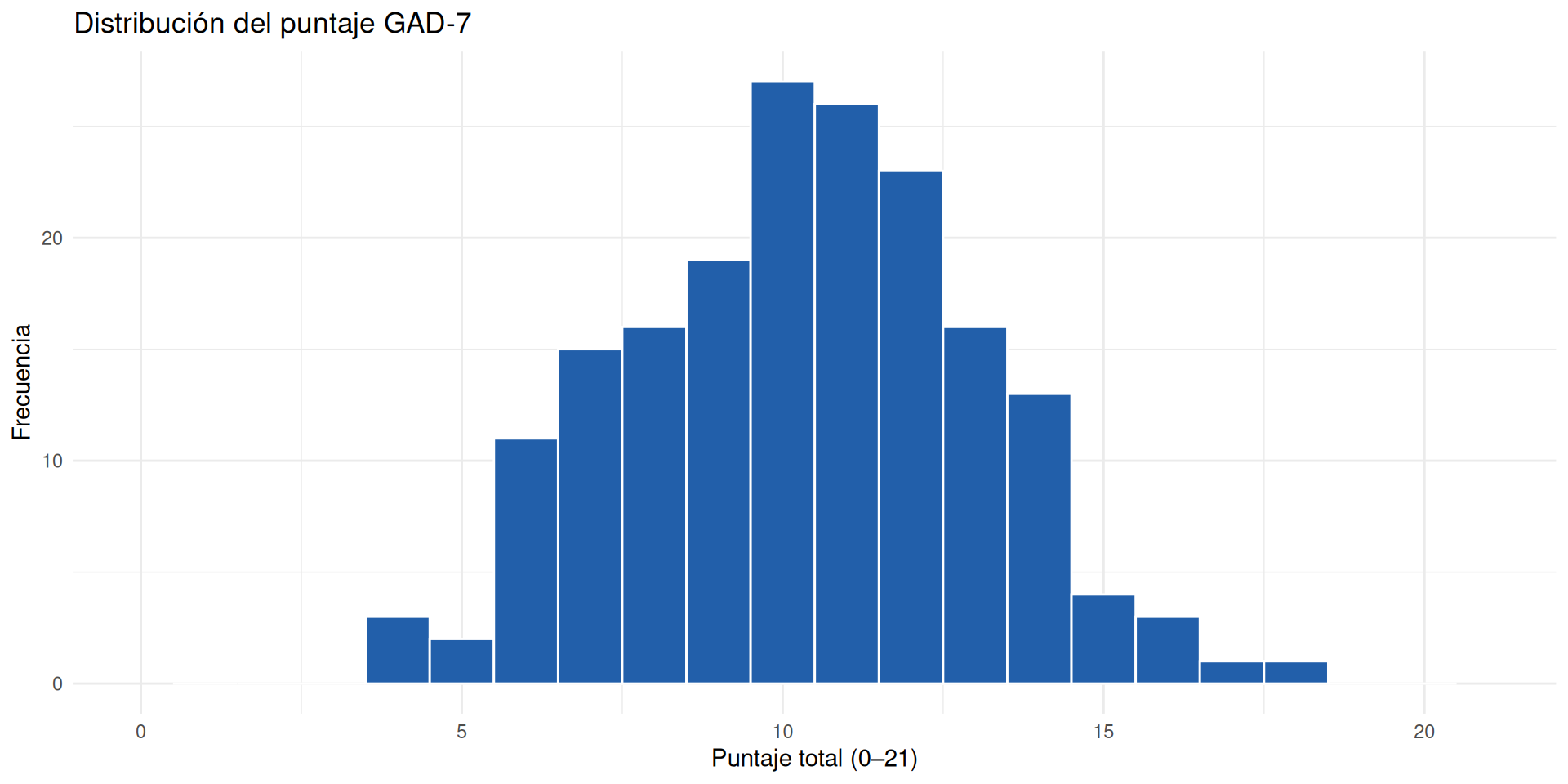
Figura 2: ansiedad por carrera
ggplot(encuesta,
aes(x = carrera,
y = ansiedad_total,
fill = carrera,
colour = carrera)
) +
geom_violin(alpha = 0.2) +
geom_jitter(
width = 0.15,
alpha = 0.4,
size = 1.5
) +
scale_fill_viridis_d() +
scale_colour_viridis_d() +
labs(
title = "Ansiedad según carrera",
x = NULL,
y = "Puntaje GAD-7"
) +
theme_minimal() +
theme(legend.position = "none")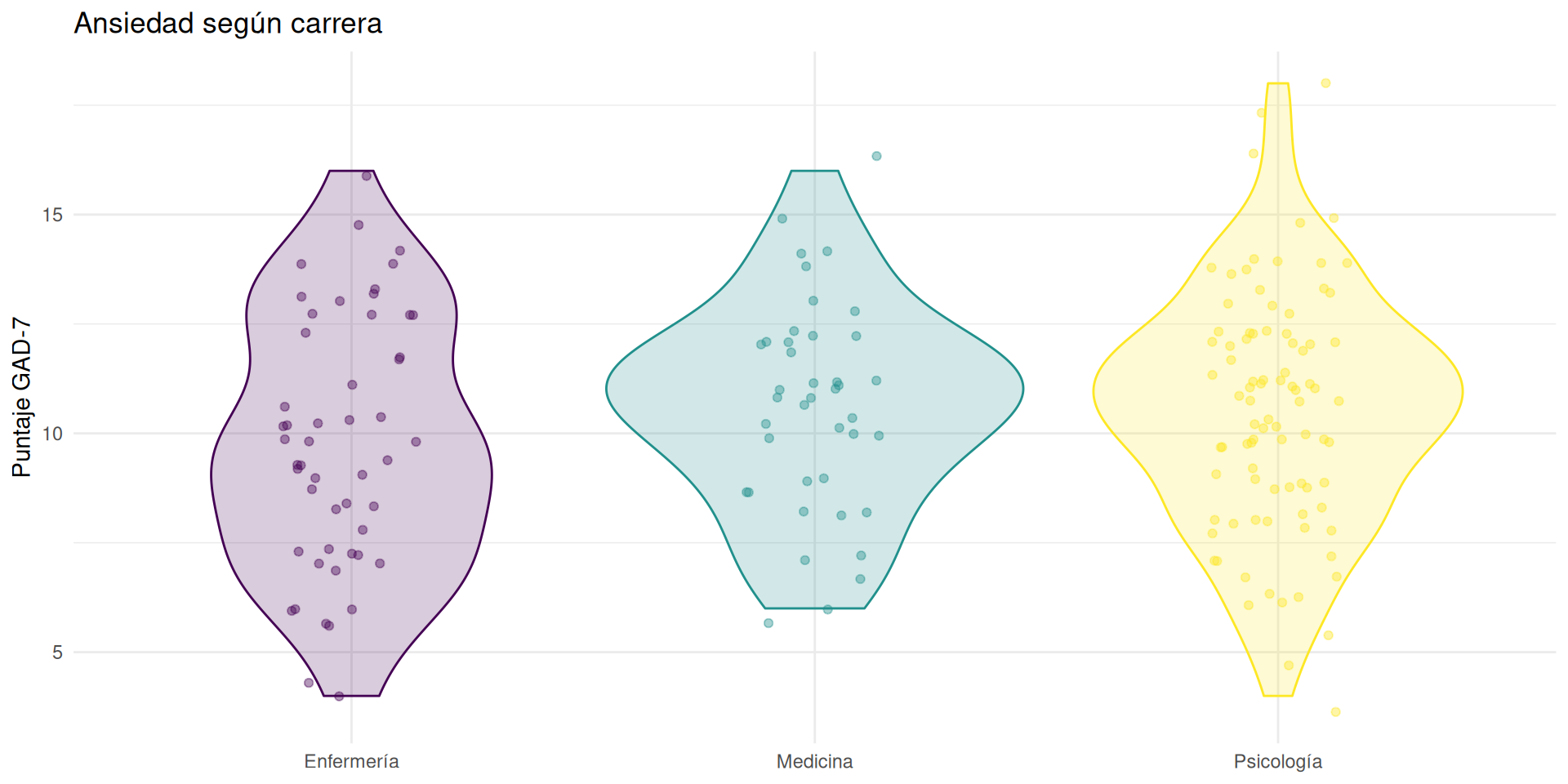
Figura 3: nivel de ansiedad por género
encuesta |>
filter(genero != "No binario") |>
ggplot(aes(
x = nivel_ansiedad,
fill = genero
)) +
geom_bar(position = "dodge") +
scale_fill_manual(values = c(
"Mujer" = "#6b1220",
"Hombre" = "#225faa"
)) +
labs(
title = "Nivel de ansiedad por género",
x = "Nivel GAD-7",
y = "Conteo",
fill = "Género"
) +
theme_minimal()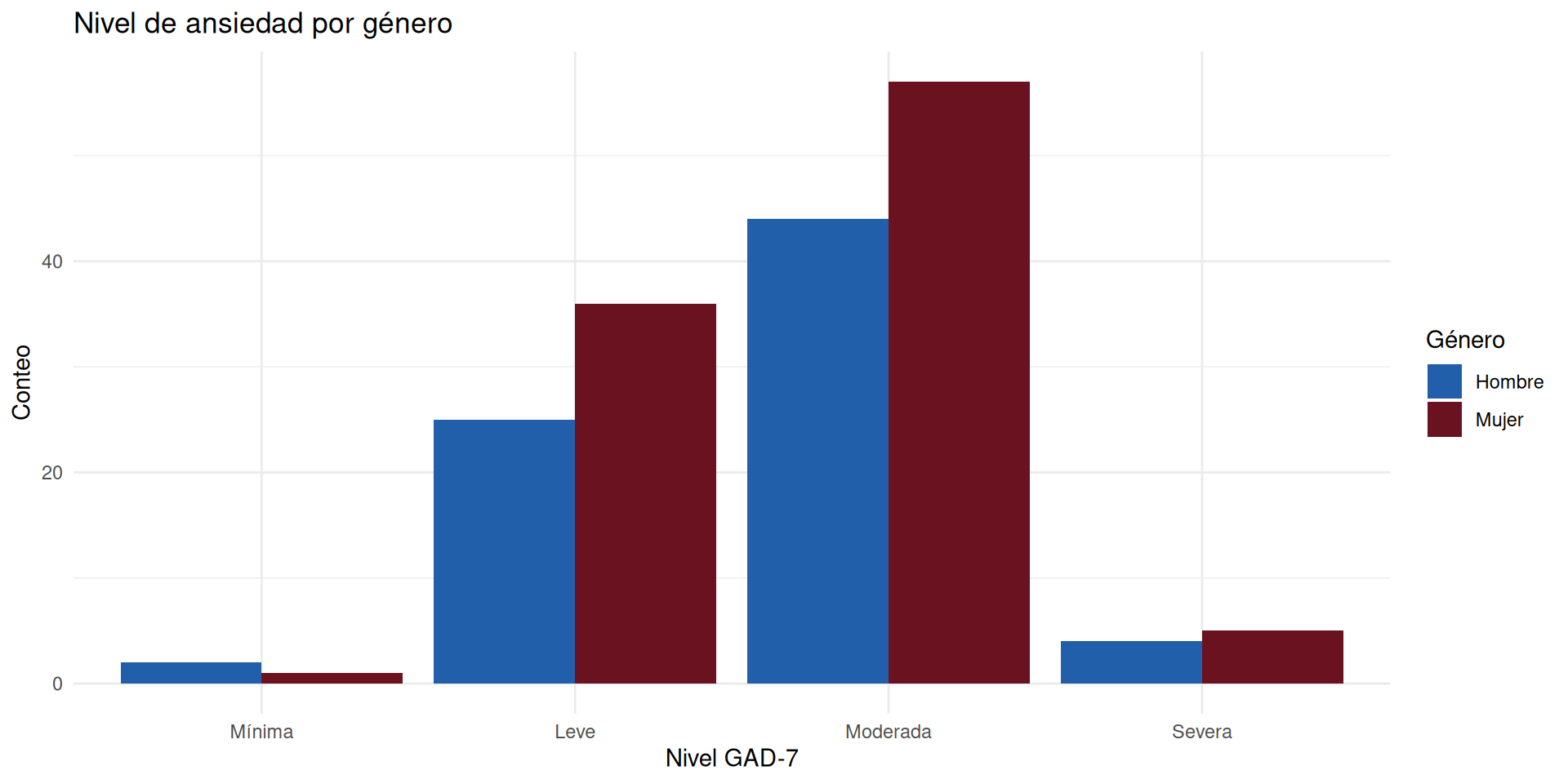
El pipeline llega hasta la figura: encuesta |> filter(...) |> ggplot(...) + geom_*(). Los datos pasan de dplyr a ggplot2 sin crear objetos intermedios.
Antes de terminar…
Quiz rápido
Quiz · 1 de 4
¿Qué hace |> en este código?
- Compara
pinguinoscon las filas de especie Adelie
- Compara
- Toma
pinguinosy lo pasa como primer argumento defilter(), devolviendo solo las filas dondespecieses"Adelie"
- Toma
- Crea un nuevo objeto llamado
filter
- Crea un nuevo objeto llamado
- Elimina la especie Adelie de la base de datos
✓ b) El pipe pasa lo que está a su izquierda como primer argumento de la función de la derecha. Es equivalente a filter(pinguinos, species == "Adelie").
Quiz · 2 de 4
¿Cuál verbo usarías para quedarte solo con las columnas species y body_mass_g?
filter(species, body_mass_g): elige filas según condición
mutate(species, body_mass_g): crea columnas nuevas
select(species, body_mass_g): elige columnas por nombre
summarise(species, body_mass_g): resume en una fila
✓ c) select() elige columnas. filter() elige filas. Son los dos verbos de “recorte”: uno actúa sobre columnas, el otro sobre filas.
Quiz · 3 de 4
¿Cuál es la diferencia entre estas dos condiciones en filter()?
filter(pinguinos, sex == "female", body_mass_g > 4000)
filter(pinguinos, sex == "female" | body_mass_g > 4000)- Son equivalentes: la coma y
|hacen lo mismo
- Son equivalentes: la coma y
- La primera usa AND (ambas condiciones); la segunda usa OR (al menos una)
- La primera usa OR; la segunda usa AND
- La segunda genera un error de sintaxis
✓ b) Con , ambas condiciones deben cumplirse (AND). Con | basta con que se cumpla una (OR). Una hembra de 3900 g entraría solo en el segundo caso: no cumple la masa, pero sí el sexo.
Quiz · 4 de 4
¿Qué produce este código?
- Una columna nueva
nañadida apinguinos
- Una columna nueva
- Un data frame con una fila por cada pingüino y su especie
- Un data frame con una fila por especie, con el conteo y la media
- Un error:
group_by()ysummarise()no se pueden encadenar
- Un error:
✓ c) group_by() agrupa las filas sin cambiarlas. summarise() colapsa cada grupo en una sola fila. El resultado tiene tantas filas como grupos: tres, una por especie.
A practicar
Usa los datos de encuesta que limpiamos hoy y explora al menos una pregunta con un pipeline completo:
encuesta |>
filter(...) |>
group_by(...) |>
summarise(...) |>
ggplot(aes(...)) +
geom_*() +
labs(...)Algunas preguntas posibles:
- ¿Varía el puntaje de ansiedad según el semestre?
- ¿Hay diferencias entre carreras en los niveles de ansiedad severa?
- ¿Cómo se distribuye la edad según el nivel de ansiedad?
Reto 1
El concurso de la figura más fea
Para la Sesión 4 · Entrega el script · El grupo vota
Reto 1: el concurso de la figura más fea
Tu misión: crear la figura estadística más horrible, ilegible y estéticamente ofensiva que seas capaz de producir en R.
- Debe generarse completamente con
ggplot2(y los paquetes que quieras) - Guarda el script
.Rcon tu nombre y súbelo aquí - El script debe comenzar por cargar los paquetes necesarios
- La presentas en la Sesión 4: máximo 3 minutos, muestras código y figura
- El grupo vota por la más fea
Inspiración (1 de 2)
Nicole Daniela Sierra, 2026
labs(
title = "GRAFICA HIPER PROFESIONAL",
subtitle = "ANALISIS SUPER CIENTIFICO",
caption = "100% REAL",
x = "EDaAaAaAD",
y = "ESTREeEEeEs"
) +
scale_color_manual(
values = c("#FFFF00", "#FF0000")
) +
theme(
plot.background = element_rect(
fill = "#FF00FF"
),
panel.background = element_rect(
fill = "#00FFFF"
),
panel.grid.major = element_line(
color = "#00FF00", linewidth = 3
)
)
Inspiración (2 de 2)
Ana Sofía Reyes, 2025
theme_dark() +
theme(
panel.background = element_rect(
fill = "yellow"
),
plot.background = element_rect(
fill = "pink"
),
legend.background = element_rect(
fill = "cyan"
)
) +
annotate("text",
x = 15, y = 300,
label = "MUCHOS DATOS",
color = "red", size = 10,
angle = 45
) +
annotate("text",
x = 30, y = 50,
label = "💥 CARROS 💥",
color = "darkgreen", size = 12,
angle = -30
)
Hasta la próxima sesión
¡Gracias!
 jdleongomez.github.io/curso-r
jdleongomez.github.io/curso-r
![]()

Curso de R · Universidad El Bosque · Junio 2026 · ↩︎ Sitio del curso