Sesión 5
Automatización: funciones, condicionales y simulación
11 de junio de 2026
Simulación de datos
Simular datos se trata de generar observaciones artificiales a partir de un modelo con propiedades conocidas o esperadas. No se trata de que lo usemos para fabricar resultados ni presentar datos falsos como reales.
Usos legítimos
- Practicar R: no necesitas esperar a tener datos propios
- Explorar distribuciones: entender visualmente qué implica un supuesto estadístico
- Ver posibles resultados: imaginar escenarios antes de recolectar datos reales
- Verificar scripts: confirmar que el código funciona antes de tener los datos definitivos
- Análisis de poder: calcular cuántas observaciones se necesitan para detectar un efecto
- Preregistro y reportes registrados: escribir y probar el análisis completo antes de recolectar datos
Es lo mismo que un simulador de vuelo para pilotos: permite practicar, probar escenarios y detectar problemas antes de enfrentarse a la situación real.

Cómo se ven las distribuciones
rnorm() · runif() · rbinom() — distribuciones paramétricas
set.seed(17)
data.frame(
Normal = rnorm(1000, mean = 10, sd = 3),
Uniforme = runif(1000, min = 0, max = 20),
Binomial = rbinom(1000, size = 20, prob = 0.3)
) |>
pivot_longer(everything(),
names_to = "dist", values_to = "valor"
) |>
mutate(dist = factor(dist,
levels = c("Normal", "Uniforme", "Binomial")
)) |>
ggplot(aes(x = valor, fill = dist)) +
geom_histogram(binwidth = 1, show.legend = FALSE) +
facet_wrap(~dist, scales = "free", nrow = 1) +
scale_fill_manual(values = c(
"Normal" = "#225faa", "Uniforme" = "#5b9ad5",
"Binomial" = "#7db87d"
)) +
labs(x = NULL, y = "Frecuencia") +
theme_minimal()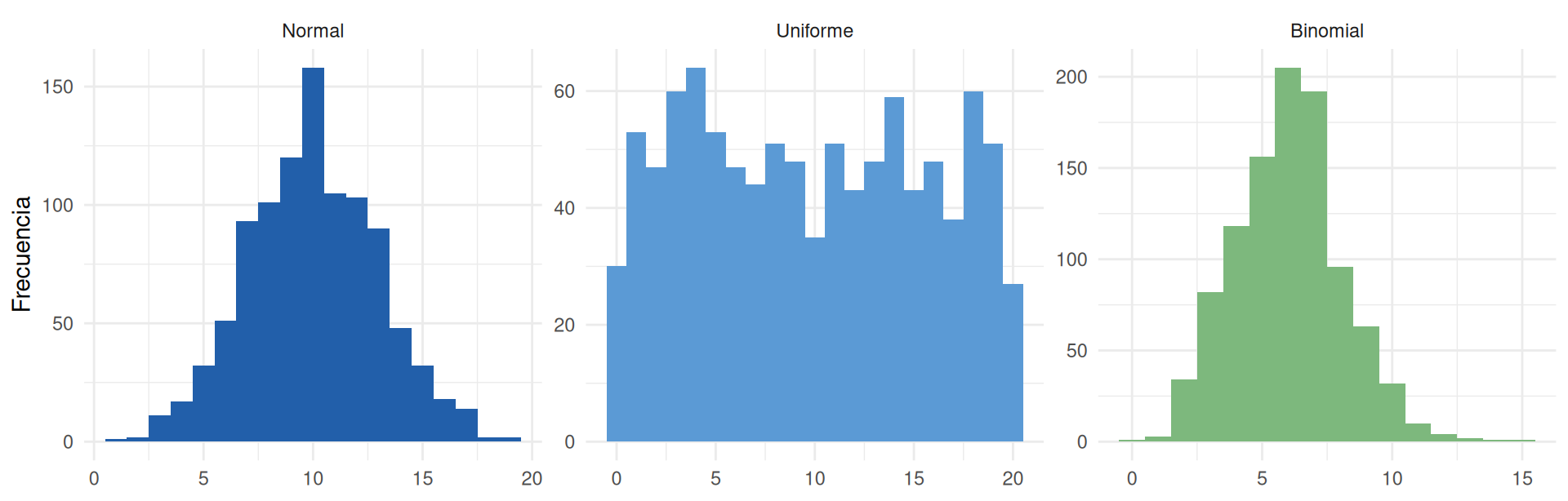
Cómo se ven las distribuciones
sample() — muestrear desde un conjunto existente
Parte 5
Variables correlacionadas con faux

La limitación de rnorm() independiente
Las variables simuladas con rnorm() por separado no tienen ninguna relación entre sí. Pero en datos reales las variables suelen estar correlacionadas: más ansiedad tiende a asociarse con menos bienestar, menos horas de sueño, etc.
Simulación independiente
set.seed(1)
ind <- data.frame(
gad7 = rnorm(500, mean = 8, sd = 5),
bienestar = rnorm(500, mean = 65, sd = 15)
)
ggplot(ind, aes(x = gad7, y = bienestar)) +
geom_point(alpha = 0.3, colour = "#225faa") +
geom_smooth(method = "lm", colour = "red", se = FALSE) +
labs(title = paste0("r = ",
round(cor(ind$gad7, ind$bienestar), 2)),
x = "GAD-7", y = "Bienestar") +
theme_minimal()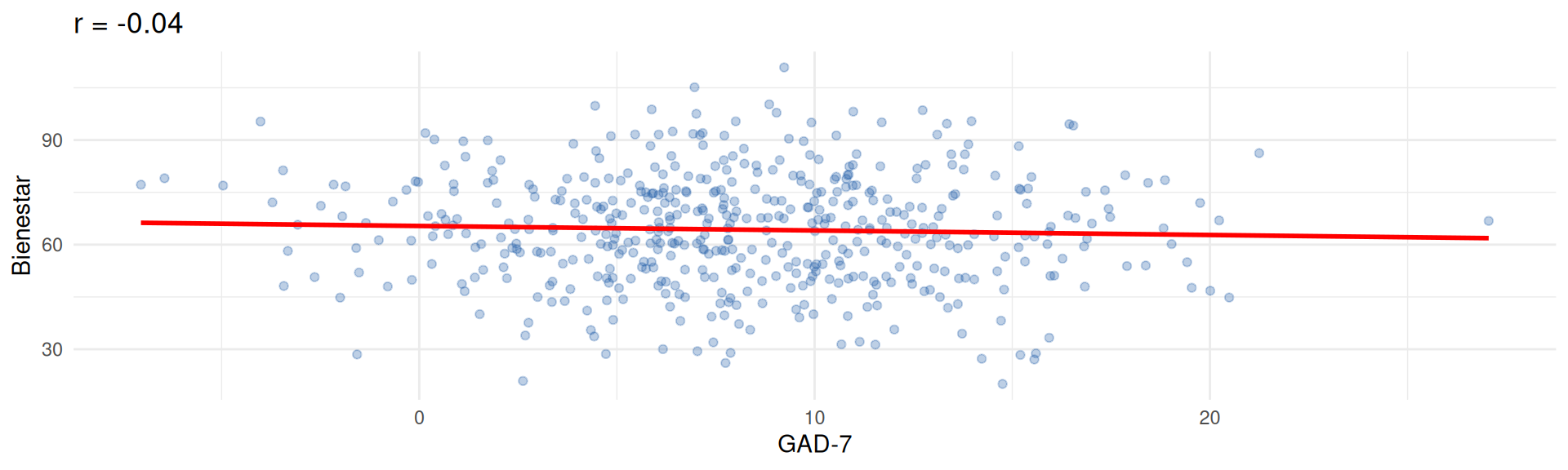
Simulación con faux
set.seed(1)
cor_dat <- rnorm_multi(n = 500,
mu = c(8, 65), sd = c(5, 15),
r = -0.45, empirical = TRUE,
varnames = c("gad7", "bienestar")
)
ggplot(cor_dat, aes(x = gad7, y = bienestar)) +
geom_point(alpha = 0.3, colour = "#225faa") +
geom_smooth(method = "lm", colour = "red", se = FALSE) +
labs(title = paste0("r = ",
round(cor(cor_dat$gad7, cor_dat$bienestar), 2)),
x = "GAD-7", y = "Bienestar") +
theme_minimal()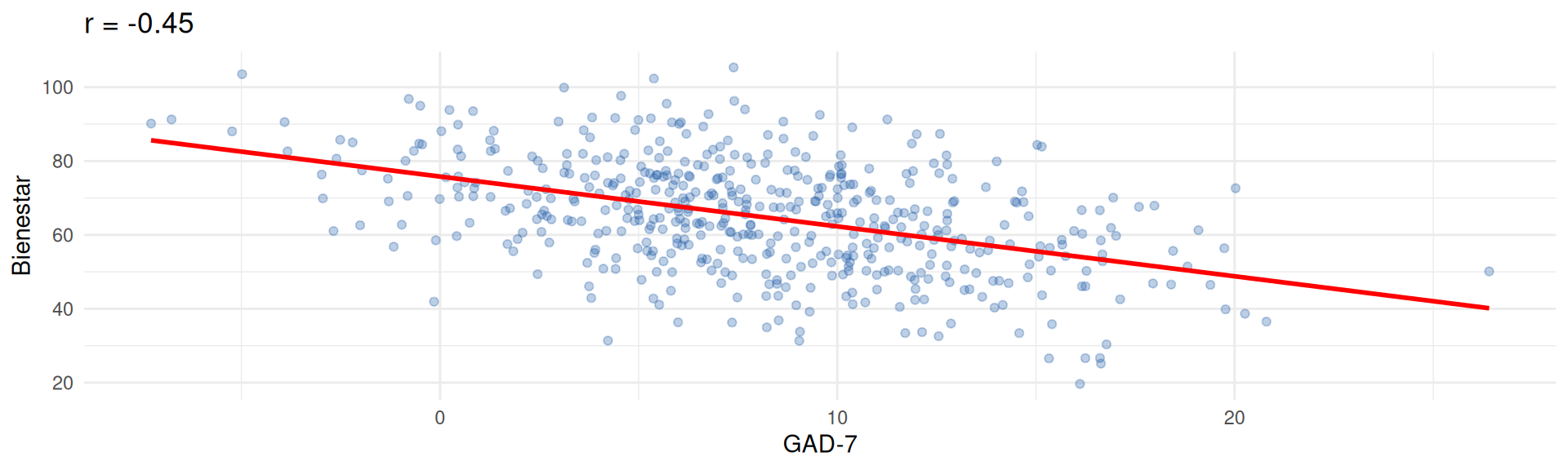
Visualizar la distribución de niveles
gad7_sim |>
mutate(nivel_ansiedad = factor(
nivel_ansiedad,
levels = c("Mínima", "Leve", "Moderada", "Severa")
)) |>
ggplot(aes(x = nivel_ansiedad, fill = nivel_ansiedad)) +
geom_bar() +
scale_fill_manual(
values = c(
"Mínima" = "#7db87d", "Leve" = "#f5c842",
"Moderada" = "#f0943a", "Severa" = "#c0392b"
)
) +
labs(x = "Nivel de ansiedad", y = "Frecuencia", fill = NULL) +
theme_minimal() +
theme(legend.position = "none")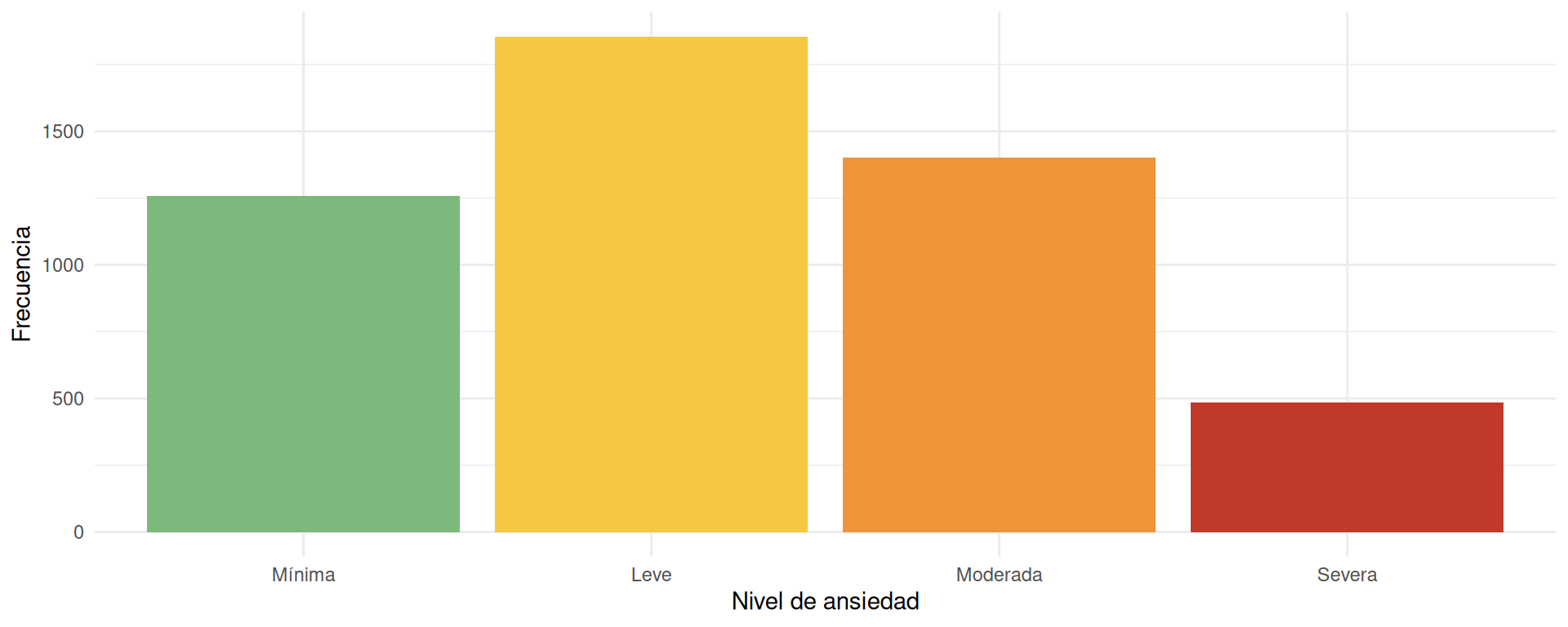
¿Qué tendrías que hacer para visualizar a distribución por carrera?
Hasta la próxima sesión
¡Gracias!
 jdleongomez.github.io/curso-r
jdleongomez.github.io/curso-r
![]()
